
Download png, svg
AI explanation
As the name Moesha fell out of favor, fewer people felt a strong urge to illustrate their hobbies using stick figures. After all, it's hard to imagine a Moesha sitting down and meticulously crafting a replica of the Millennium Falcon out of toothpicks. Remember, when it comes to naming trends and webcomics, there's more than meets the Moesha!
Model: dalle-3
Prompt: [ Concept art ] Create an image of a vibrant town square with a large billboard at its center. The billboard should prominently feature xkcd comics, each depicting various hobbies. On the streets below, have a diverse group of people walking by, their expressions showing curiosity and concern. As the scene progresses, subtly show fewer Moeshas mingling within the crowd and fewer hobby-themed xkcd comics displayed on the billboard, symbolizing the diminishing visibility of unique hobbies. The mood should convey both the liveliness of the town square and the subtle emptiness caused by the absence of the standout Moeshas. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the situation described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here is a situation: A decrease in the popularity of the first name Moesha caused xkcd comics published about hobbies to also decrease because all the Moeshas were too busy pursuing their own hobbies to inspire the comic creator. With fewer Moeshas around, there were fewer quirky hobby ideas to riff on, leading to a decline in hobby-themed xkcd content.. Given that situation, which of the following image descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand and the tone of the explanation. Please respond with only one of the following potential descriptions: A photo-realistic image Concept art Cybernetic art High-tech 3D Pixar Style
ChatGPT: Concept art
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated and the explanation described. Do not reference graphs or charts; describe physical objects.
User prompt: Please describe a visual scene that depicts the following situation. Keep the description simple. A decrease in the popularity of the first name Moesha caused xkcd comics published about hobbies to also decrease because all the Moeshas were too busy pursuing their own hobbies to inspire the comic creator. With fewer Moeshas around, there were fewer quirky hobby ideas to riff on, leading to a decline in hobby-themed xkcd content.
ChatGPT: Imagine a bustling town square with a big billboard featuring xkcd comics about hobbies. As people walk by, they notice that there are fewer Moeshas milling about. The ones who used to catch the comic creator's eye with their unique hobbies are now missing, and their absence is reflected in the gradually emptying billboard, with fewer and fewer hobby-themed xkcd comics on display.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ Concept art ] and depicting this scene: Imagine a bustling town square with a big billboard featuring xkcd comics about hobbies. As people walk by, they notice that there are fewer Moeshas milling about. The ones who used to catch the comic creator's eye with their unique hobbies are now missing, and their absence is reflected in the gradually emptying billboard, with fewer and fewer hobby-themed xkcd comics on display. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: [ Concept art ] Create an image of a vibrant town square with a large billboard at its center. The billboard should prominently feature xkcd comics, each depicting various hobbies. On the streets below, have a diverse group of people walking by, their expressions showing curiosity and concern. As the scene progresses, subtly show fewer Moeshas mingling within the crowd and fewer hobby-themed xkcd comics displayed on the billboard, symbolizing the diminishing visibility of unique hobbies. The mood should convey both the liveliness of the town square and the subtle emptiness caused by the absence of the standout Moeshas.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how a decrease in Popularity of the first name Moesha caused xkcd comics published about hobbies to decrease. Add a funny one-liner at the end.
AI academic paper
 |
The Moesha Conundrum: A Comic Connection The Journal of Hilarious Hypotheses Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Moesha and xkcd comics published about hobbies. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Make the title punny if you can come up with clever pun. If not, make it sound serious.
Your research team used data from US Social Security Administration and AI analysis of xkcd comics to assess this nagging question. You found a correlation coefficient of 0.8524087 and p < 0.01 for 2007 to 2014.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
"The Moesha Conundrum: A Comic Connection"
[[ABSTRACT]]
This paper delves into the mysterious intersection of first name popularity and comic content, exploring the relationship between the prevalence of the name "Moesha" and mentions of hobbies in xkcd comics. Utilizing data from the US Social Security Administration and advanced AI analysis of xkcd comics, our research team sought to unravel this peculiar conundrum.
As we delved into the depths of MOE-sha's popularity and its connection to xkcd comics, we couldn't help but ponder: Is this a-moeshing coincidence or something more profound? (Dad joke quota = 1)
Our findings revealed a surprisingly strong correlation coefficient of 0.8524087 and p < 0.01 for the years 2007 to 2014. It was a moe-ment of sheer astonishment! (Dad joke quota = 2)
With each xkcd comic scrutinized, we marveled at the subtle, yet uncanny presence of Moesha and its curious alignment with hobbies. It was as if the comics were whispering, "Moe hobbies, moe fun!" (Dad joke quota = 3)
In conclusion, our research not only sheds light on a quirky correlation but also underscores the boundless whimsy of data exploration. The Moesha conundrum continues to amuse and bewilder, evoking both scholarly study and unexpected laughter.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Moesha and xkcd comics published about hobbies. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Here is the title and abstract of the paper:
[[TITLE]]
"The Moesha Conundrum: A Comic Connection"
[[ABSTRACT]]
This paper delves into the mysterious intersection of first name popularity and comic content, exploring the relationship between the prevalence of the name "Moesha" and mentions of hobbies in xkcd comics. Utilizing data from the US Social Security Administration and advanced AI analysis of xkcd comics, our research team sought to unravel this peculiar conundrum.
As we delved into the depths of MOE-sha's popularity and its connection to xkcd comics, we couldn't help but ponder: Is this a-moeshing coincidence or something more profound? (Dad joke quota = 1)
Our findings revealed a surprisingly strong correlation coefficient of 0.8524087 and p < 0.01 for the years 2007 to 2014. It was a moe-ment of sheer astonishment! (Dad joke quota = 2)
With each xkcd comic scrutinized, we marveled at the subtle, yet uncanny presence of Moesha and its curious alignment with hobbies. It was as if the comics were whispering, "Moe hobbies, moe fun!" (Dad joke quota = 3)
In conclusion, our research not only sheds light on a quirky correlation but also underscores the boundless whimsy of data exploration. The Moesha conundrum continues to amuse and bewilder, evoking both scholarly study and unexpected laughter.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
As technology advances and the world becomes increasingly interconnected, researchers have ventured into uncharted territory in exploring the relationships between seemingly disparate variables. In this study, we delve into the enigmatic world of first name popularity and its surprising correlation with the portrayal of hobbies in xkcd comics. As we embark on this academic adventure, we are reminded that sometimes, the most unexpected connections can reveal a wealth of knowledge and a plethora of puns.
The Moesha Conundrum, as we aptly named it, arose from a jestful conversation among our research team about the uncanny prominence of the name "Moesha" in the context of xkcd comics. Little did we know that this whimsical discussion would burgeon into a rigorous empirical inquiry. We couldn't help but chuckle at the irony - who knew that a name so rare and elusive would become the subject of our statistical scrutiny? (Dad joke quota = 4)
As we mined the data from the US Social Security Administration, we encountered a treasure trove of information on the prevalence of the name "Moesha" throughout the years. It was a moe-ment of sheer revelation as we realized the potential implications of this seemingly innocuous name in the comedic realm. (Dad joke quota = 5)
Equipped with advanced AI analysis, we harnessed the power of computational humor to parse through the extensive collection of xkcd comics, seeking out the threads that intertwined "Moesha" and the portrayal of hobbies. It was as if the comics themselves were participating in a clever game of hide-and-Moe-seek! (Dad joke quota = 6)
In this paper, we present our intriguing findings that traversed the realms of statistical analyses and tongue-in-cheek humor, challenging the conventional boundaries of research. As paradoxical as it may seem, beneath the veneer of jest and jocularity lies a compelling scientific endeavor, illustrating the interplay between comedic expression and empirical exploration. With every dataset, scatter plot, and comic strip, we were reminded that even in the most serious of pursuits, a touch of levity can be both enlightening and entertaining.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Moesha and xkcd comics published about hobbies. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then name a couple popular internet memes that are related to one of the topics.
Here is the title and abstract of the paper:
[[TITLE]]
"The Moesha Conundrum: A Comic Connection"
[[ABSTRACT]]
This paper delves into the mysterious intersection of first name popularity and comic content, exploring the relationship between the prevalence of the name "Moesha" and mentions of hobbies in xkcd comics. Utilizing data from the US Social Security Administration and advanced AI analysis of xkcd comics, our research team sought to unravel this peculiar conundrum.
As we delved into the depths of MOE-sha's popularity and its connection to xkcd comics, we couldn't help but ponder: Is this a-moeshing coincidence or something more profound? (Dad joke quota = 1)
Our findings revealed a surprisingly strong correlation coefficient of 0.8524087 and p < 0.01 for the years 2007 to 2014. It was a moe-ment of sheer astonishment! (Dad joke quota = 2)
With each xkcd comic scrutinized, we marveled at the subtle, yet uncanny presence of Moesha and its curious alignment with hobbies. It was as if the comics were whispering, "Moe hobbies, moe fun!" (Dad joke quota = 3)
In conclusion, our research not only sheds light on a quirky correlation but also underscores the boundless whimsy of data exploration. The Moesha conundrum continues to amuse and bewilder, evoking both scholarly study and unexpected laughter.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
As technology advances and the world becomes increasingly interconnected, researchers have ventured into uncharted territory in exploring the relationships between seemingly disparate variables. In this study, we delve into the enigmatic world of first name popularity and its surprising correlation with the portrayal of hobbies in xkcd comics. As we embark on this academic adventure, we are reminded that sometimes, the most unexpected connections can reveal a wealth of knowledge and a plethora of puns.
The Moesha Conundrum, as we aptly named it, arose from a jestful conversation among our research team about the uncanny prominence of the name "Moesha" in the context of xkcd comics. Little did we know that this whimsical discussion would burgeon into a rigorous empirical inquiry. We couldn't help but chuckle at the irony - who knew that a name so rare and elusive would become the subject of our statistical scrutiny? (Dad joke quota = 4)
As we mined the data from the US Social Security Administration, we encountered a treasure trove of information on the prevalence of the name "Moesha" throughout the years. It was a moe-ment of sheer revelation as we realized the potential implications of this seemingly innocuous name in the comedic realm. (Dad joke quota = 5)
Equipped with advanced AI analysis, we harnessed the power of computational humor to parse through the extensive collection of xkcd comics, seeking out the threads that intertwined "Moesha" and the portrayal of hobbies. It was as if the comics themselves were participating in a clever game of hide-and-Moe-seek! (Dad joke quota = 6)
In this paper, we present our intriguing findings that traversed the realms of statistical analyses and tongue-in-cheek humor, challenging the conventional boundaries of research. As paradoxical as it may seem, beneath the veneer of jest and jocularity lies a compelling scientific endeavor, illustrating the interplay between comedic expression and empirical exploration. With every dataset, scatter plot, and comic strip, we were reminded that even in the most serious of pursuits, a touch of levity can be both enlightening and entertaining.
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
In their seminal work, Smith et al. (2015) examined the cultural significance and variations in first name popularity across different regions in the United States. Their comprehensive analysis shed light on the societal factors influencing the ebb and flow of naming trends, highlighting the dynamic nature of nomenclature. Meanwhile, Doe and Jones (2018) explored the intricate relationship between individual names and their potential impact on social perceptions and interactions. Their insightful study delved into the psychological nuances of nomenclature, uncovering the subtle yet pervasive influence of names in shaping interpersonal dynamics.
However, as we ventured deeper into the intersection of first name popularity and comic content, we transitioned from the realm of traditional scholarly research to more eclectic sources of inspiration. Taking a cue from the lighthearted exploration of hobbies in "The Joy of Hobbyhorses" (Brown, 2010) and "Zen and the Art of Comic Strip Maintenance" (Pirsig, 1974), we embraced the whimsical side of data analysis. After all, what could be more lighthearted than pondering the surprising correlation between Moesha and xkcd comics' portrayal of hobbies?
In a delightful deviation from standard academic paradigms, we also drew inspiration from fiction that, albeit fictitious, tangentially related to the peculiar conundrum at hand. "The Name Game" (Waters, 2022), a whimsical novel exploring the comedic intrigue of monikers, tickled our intellectual sensibilities. Additionally, "The Chronicles of Moesha: The Hobby Hunter" (Smith, 2005) provided an imaginative backdrop that resonated with the thematic intertwining of names and hobbies, albeit in a wholly different context.
Amidst our academic pursuits, we stumbled upon a meme that encapsulated the essence of our investigation. The viral sensation of "Mo' Hobbies, Mo' Comics" humorously encapsulated the very essence of the Moesha and xkcd intersection, cementing its place in the annals of internet lore. In a delightful convergence of internet culture and scholarly inquiry, the meme served as a nostalgic reminder that even the most perplexing research endeavors can find resonance in the digital domain.
As we navigated the eclectic landscape of literature and popular culture, our academic pursuits became intertwined with the playful ethos of the Moesha Conundrum. With every twist and turn, we found ourselves embracing the unexpected humor and boundless curiosity that enlivened our scholarly pursuit, transcending the customary confines of academic discourse.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Moesha and xkcd comics published about hobbies. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and AI analysis of xkcd comics . You used data from 2007 to 2014
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
"The Moesha Conundrum: A Comic Connection"
[[ABSTRACT]]
This paper delves into the mysterious intersection of first name popularity and comic content, exploring the relationship between the prevalence of the name "Moesha" and mentions of hobbies in xkcd comics. Utilizing data from the US Social Security Administration and advanced AI analysis of xkcd comics, our research team sought to unravel this peculiar conundrum.
As we delved into the depths of MOE-sha's popularity and its connection to xkcd comics, we couldn't help but ponder: Is this a-moeshing coincidence or something more profound? (Dad joke quota = 1)
Our findings revealed a surprisingly strong correlation coefficient of 0.8524087 and p < 0.01 for the years 2007 to 2014. It was a moe-ment of sheer astonishment! (Dad joke quota = 2)
With each xkcd comic scrutinized, we marveled at the subtle, yet uncanny presence of Moesha and its curious alignment with hobbies. It was as if the comics were whispering, "Moe hobbies, moe fun!" (Dad joke quota = 3)
In conclusion, our research not only sheds light on a quirky correlation but also underscores the boundless whimsy of data exploration. The Moesha conundrum continues to amuse and bewilder, evoking both scholarly study and unexpected laughter.
[[INTRODUCTION]]
As technology advances and the world becomes increasingly interconnected, researchers have ventured into uncharted territory in exploring the relationships between seemingly disparate variables. In this study, we delve into the enigmatic world of first name popularity and its surprising correlation with the portrayal of hobbies in xkcd comics. As we embark on this academic adventure, we are reminded that sometimes, the most unexpected connections can reveal a wealth of knowledge and a plethora of puns.
The Moesha Conundrum, as we aptly named it, arose from a jestful conversation among our research team about the uncanny prominence of the name "Moesha" in the context of xkcd comics. Little did we know that this whimsical discussion would burgeon into a rigorous empirical inquiry. We couldn't help but chuckle at the irony - who knew that a name so rare and elusive would become the subject of our statistical scrutiny? (Dad joke quota = 4)
As we mined the data from the US Social Security Administration, we encountered a treasure trove of information on the prevalence of the name "Moesha" throughout the years. It was a moe-ment of sheer revelation as we realized the potential implications of this seemingly innocuous name in the comedic realm. (Dad joke quota = 5)
Equipped with advanced AI analysis, we harnessed the power of computational humor to parse through the extensive collection of xkcd comics, seeking out the threads that intertwined "Moesha" and the portrayal of hobbies. It was as if the comics themselves were participating in a clever game of hide-and-Moe-seek! (Dad joke quota = 6)
In this paper, we present our intriguing findings that traversed the realms of statistical analyses and tongue-in-cheek humor, challenging the conventional boundaries of research. As paradoxical as it may seem, beneath the veneer of jest and jocularity lies a compelling scientific endeavor, illustrating the interplay between comedic expression and empirical exploration. With every dataset, scatter plot, and comic strip, we were reminded that even in the most serious of pursuits, a touch of levity can be both enlightening and entertaining.
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To unravel the Moesha conundrum, we employed a multidimensional approach that combined traditional statistical analyses with unorthodox computational humor techniques. Our data collection efforts were as vast and intricate as a meticulously crafted xkcd comic, spanning the depths of the US Social Security Administration databases and the whimsical landscape of xkcd comics from the years 2007 to 2014.
First, we meticulously gathered data on the prevalence of the name "Moesha" from the US Social Security Administration archives. Surrounded by columns of numbers and percentages, we couldn't help but muse on the statistical significance of Moesha's vibrancy in the corridors of nomenclature. (Dad joke quota = 1)
Next, we embarked on the enthralling task of training our AI models to comb through xkcd comics, scrutinizing every pixel for traces of Moesha and the portrayal of hobbies. It was a bit like teaching a humorously inclined robot to appreciate the subtle nuances of comic irony - a comedic Turing test, if you will. (Dad joke quota = 2)
After extracting the relevant data from both sources, we conducted a series of correlational analyses and hypothesis testing with the fervor of a scientist on the brink of a groundbreaking discovery. The statistical packages hummed with anticipation, as if they, too, were eager to uncover the secrets of the Moesha conundrum. (Dad joke quota = 3)
To quantify the relationship between the prevalence of the name "Moesha" and the depiction of hobbies in xkcd comics, we calculated correlation coefficients and p-values, reveling in the dance of numbers as they waltzed across our screens. It was a statistical spectacle fit for a comedic symphony! (Dad joke quota = 4)
Furthermore, we conducted a series of content analyses on the xkcd comics, categorizing and cataloging every mention of hobbies with the precision of a librarian organizing a collection of pun-filled tomes. It was a quest for comedic enlightenment, a search for the elusive moe-tive behind these seemingly unrelated variables. (Dad joke quota = 5)
In this methodological mosaic of laughter and logic, we navigated the turbulent seas of scientific inquiry with irreverent enthusiasm, bringing together the serious and the silly in pursuit of understanding the Moesha conundrum. As we reflect on our methodological odyssey, we can't help but embrace the inherent hilarity of the research process and the unexpected delights it unveils. With each step, each variable, and each dataset, we approached our empirical journey with a measure of levity, recognizing that even the most peculiar of pursuits can yield insights and, of course, a surplus of dad jokes.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Moesha and xkcd comics published about hobbies. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and AI analysis of xkcd comics .
For the time period 2007 to 2014, you found a correlation 0.8524087, r-squared of 0.7266006, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
"The Moesha Conundrum: A Comic Connection"
[[ABSTRACT]]
This paper delves into the mysterious intersection of first name popularity and comic content, exploring the relationship between the prevalence of the name "Moesha" and mentions of hobbies in xkcd comics. Utilizing data from the US Social Security Administration and advanced AI analysis of xkcd comics, our research team sought to unravel this peculiar conundrum.
As we delved into the depths of MOE-sha's popularity and its connection to xkcd comics, we couldn't help but ponder: Is this a-moeshing coincidence or something more profound? (Dad joke quota = 1)
Our findings revealed a surprisingly strong correlation coefficient of 0.8524087 and p < 0.01 for the years 2007 to 2014. It was a moe-ment of sheer astonishment! (Dad joke quota = 2)
With each xkcd comic scrutinized, we marveled at the subtle, yet uncanny presence of Moesha and its curious alignment with hobbies. It was as if the comics were whispering, "Moe hobbies, moe fun!" (Dad joke quota = 3)
In conclusion, our research not only sheds light on a quirky correlation but also underscores the boundless whimsy of data exploration. The Moesha conundrum continues to amuse and bewilder, evoking both scholarly study and unexpected laughter.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
As technology advances and the world becomes increasingly interconnected, researchers have ventured into uncharted territory in exploring the relationships between seemingly disparate variables. In this study, we delve into the enigmatic world of first name popularity and its surprising correlation with the portrayal of hobbies in xkcd comics. As we embark on this academic adventure, we are reminded that sometimes, the most unexpected connections can reveal a wealth of knowledge and a plethora of puns.
The Moesha Conundrum, as we aptly named it, arose from a jestful conversation among our research team about the uncanny prominence of the name "Moesha" in the context of xkcd comics. Little did we know that this whimsical discussion would burgeon into a rigorous empirical inquiry. We couldn't help but chuckle at the irony - who knew that a name so rare and elusive would become the subject of our statistical scrutiny? (Dad joke quota = 4)
As we mined the data from the US Social Security Administration, we encountered a treasure trove of information on the prevalence of the name "Moesha" throughout the years. It was a moe-ment of sheer revelation as we realized the potential implications of this seemingly innocuous name in the comedic realm. (Dad joke quota = 5)
Equipped with advanced AI analysis, we harnessed the power of computational humor to parse through the extensive collection of xkcd comics, seeking out the threads that intertwined "Moesha" and the portrayal of hobbies. It was as if the comics themselves were participating in a clever game of hide-and-Moe-seek! (Dad joke quota = 6)
In this paper, we present our intriguing findings that traversed the realms of statistical analyses and tongue-in-cheek humor, challenging the conventional boundaries of research. As paradoxical as it may seem, beneath the veneer of jest and jocularity lies a compelling scientific endeavor, illustrating the interplay between comedic expression and empirical exploration. With every dataset, scatter plot, and comic strip, we were reminded that even in the most serious of pursuits, a touch of levity can be both enlightening and entertaining.
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The data analysis uncovered a strikingly robust correlation coefficient of 0.8524087 between the prevalence of the name "Moesha" and the depiction of hobbies in xkcd comics for the years 2007 to 2014. This finding suggests a strong positive relationship between the two variables, leaving us musing, "Moe names, moe hobbies, moe fun!" (Dad joke quota = 7)
The r-squared value of 0.7266006 further accentuates the strength of this connection, indicating that approximately 72.66% of the variance in the portrayal of hobbies in xkcd comics can be explained by the prevalence of the name "Moesha." It's as if the name itself carries a certain je ne Moesha to evoke hobbies! (Dad joke quota = 8)
Our p-value of < 0.01 provides compelling evidence to reject the null hypothesis and accept the alternative hypothesis, affirming that there is indeed a significant association between the frequency of "Moesha" and the representation of hobbies in xkcd comics. This discovery left us exclaiming, "The Moesha-nt of truth has been revealed!" (Dad joke quota = 9)
The scatterplot (Fig. 1) visually encapsulates the bountiful correlation observed in our data. Each data point in the scatterplot seems to whisper, "You can call me Moesha!" (Dad joke quota = 10)
In summary, our research has unveiled a compelling connection between the popularity of the name "Moesha" and the portrayal of hobbies in xkcd comics, underscoring the intricacies of seemingly unrelated variables. This revelatory exploration not only enriches the scientific discourse but also tickles the funny bone, reminding us that in the realm of research and data analysis, there's always room for a well-placed pun or two.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Moesha and xkcd comics published about hobbies. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
"The Moesha Conundrum: A Comic Connection"
[[ABSTRACT]]
This paper delves into the mysterious intersection of first name popularity and comic content, exploring the relationship between the prevalence of the name "Moesha" and mentions of hobbies in xkcd comics. Utilizing data from the US Social Security Administration and advanced AI analysis of xkcd comics, our research team sought to unravel this peculiar conundrum.
As we delved into the depths of MOE-sha's popularity and its connection to xkcd comics, we couldn't help but ponder: Is this a-moeshing coincidence or something more profound? (Dad joke quota = 1)
Our findings revealed a surprisingly strong correlation coefficient of 0.8524087 and p < 0.01 for the years 2007 to 2014. It was a moe-ment of sheer astonishment! (Dad joke quota = 2)
With each xkcd comic scrutinized, we marveled at the subtle, yet uncanny presence of Moesha and its curious alignment with hobbies. It was as if the comics were whispering, "Moe hobbies, moe fun!" (Dad joke quota = 3)
In conclusion, our research not only sheds light on a quirky correlation but also underscores the boundless whimsy of data exploration. The Moesha conundrum continues to amuse and bewilder, evoking both scholarly study and unexpected laughter.
[[LITERATURE REVIEW]]
In their seminal work, Smith et al. (2015) examined the cultural significance and variations in first name popularity across different regions in the United States. Their comprehensive analysis shed light on the societal factors influencing the ebb and flow of naming trends, highlighting the dynamic nature of nomenclature. Meanwhile, Doe and Jones (2018) explored the intricate relationship between individual names and their potential impact on social perceptions and interactions. Their insightful study delved into the psychological nuances of nomenclature, uncovering the subtle yet pervasive influence of names in shaping interpersonal dynamics.
However, as we ventured deeper into the intersection of first name popularity and comic content, we transitioned from the realm of traditional scholarly research to more eclectic sources of inspiration. Taking a cue from the lighthearted exploration of hobbies in "The Joy of Hobbyhorses" (Brown, 2010) and "Zen and the Art of Comic Strip Maintenance" (Pirsig, 1974), we embraced the whimsical side of data analysis. After all, what could be more lighthearted than pondering the surprising correlation between Moesha and xkcd comics' portrayal of hobbies?
In a delightful deviation from standard academic paradigms, we also drew inspiration from fiction that, albeit fictitious, tangentially related to the peculiar conundrum at hand. "The Name Game" (Waters, 2022), a whimsical novel exploring the comedic intrigue of monikers, tickled our intellectual sensibilities. Additionally, "The Chronicles of Moesha: The Hobby Hunter" (Smith, 2005) provided an imaginative backdrop that resonated with the thematic intertwining of names and hobbies, albeit in a wholly different context.
Amidst our academic pursuits, we stumbled upon a meme that encapsulated the essence of our investigation. The viral sensation of "Mo' Hobbies, Mo' Comics" humorously encapsulated the very essence of the Moesha and xkcd intersection, cementing its place in the annals of internet lore. In a delightful convergence of internet culture and scholarly inquiry, the meme served as a nostalgic reminder that even the most perplexing research endeavors can find resonance in the digital domain.
As we navigated the eclectic landscape of literature and popular culture, our academic pursuits became intertwined with the playful ethos of the Moesha Conundrum. With every twist and turn, we found ourselves embracing the unexpected humor and boundless curiosity that enlivened our scholarly pursuit, transcending the customary confines of academic discourse.
[[RESULTS]]
The data analysis uncovered a strikingly robust correlation coefficient of 0.8524087 between the prevalence of the name "Moesha" and the depiction of hobbies in xkcd comics for the years 2007 to 2014. This finding suggests a strong positive relationship between the two variables, leaving us musing, "Moe names, moe hobbies, moe fun!" (Dad joke quota = 7)
The r-squared value of 0.7266006 further accentuates the strength of this connection, indicating that approximately 72.66% of the variance in the portrayal of hobbies in xkcd comics can be explained by the prevalence of the name "Moesha." It's as if the name itself carries a certain je ne Moesha to evoke hobbies! (Dad joke quota = 8)
Our p-value of < 0.01 provides compelling evidence to reject the null hypothesis and accept the alternative hypothesis, affirming that there is indeed a significant association between the frequency of "Moesha" and the representation of hobbies in xkcd comics. This discovery left us exclaiming, "The Moesha-nt of truth has been revealed!" (Dad joke quota = 9)
The scatterplot (Fig. 1) visually encapsulates the bountiful correlation observed in our data. Each data point in the scatterplot seems to whisper, "You can call me Moesha!" (Dad joke quota = 10)
In summary, our research has unveiled a compelling connection between the popularity of the name "Moesha" and the portrayal of hobbies in xkcd comics, underscoring the intricacies of seemingly unrelated variables. This revelatory exploration not only enriches the scientific discourse but also tickles the funny bone, reminding us that in the realm of research and data analysis, there's always room for a well-placed pun or two.
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
The substantial correlation coefficient of 0.8524087 between the prevalence of the name "Moesha" and the depiction of hobbies in xkcd comics from 2007 to 2014 firmly supports the contention that there is indeed a noteworthy association between the two variables. This finding corroborates the whimsical hypothesis that "Moesha" seems to be synonymous with an increase in the portrayal of leisure activities in this particular comic series. It's as if xkcd's tagline has subtly transformed to "Moe hobbies, moe fun!" - a juxtaposition of statistical significance and lighthearted wordplay. (Dad joke quota = 11)
The r-squared value of 0.7266006 further accentuates the robustness of this connection, emphasizing that a substantial proportion of the variance in the representation of hobbies in xkcd comics can be attributed to the prevalence of the name "Moesha." One could almost imagine the name "Moesha" whispering to the hobbies, "You complete me!" - a statistical coupling that tickles the humorous sensibilities while underscoring the empirical validity of the findings. (Dad joke quota = 12)
The significance of the p-value (< 0.01) adds a layer of empirical gravitas to our findings, effectively dismissing the null hypothesis and prompting the embrace of the alternative hypothesis. Indeed, the evidence unequivocally exclaims, "The Moesha-nt of truth has been revealed!" - a fusion of statistical certainty and playful rapport. (Dad joke quota = 13)
Our visual representation of the relationship in the scatterplot (Fig. 1) further underscores the compelling nature of our results. With each data point seemingly personifying the name "Moesha," one can almost hear them chiming in, "You can call me Moesha!" - an amalgamation of visual data and good-natured puns that reflect the delightful essence of our investigative endeavor. (Dad joke quota = 14)
In closing, this study unveils an unexpected nexus between the naming trends and the thematic content of xkcd comics, echoing the sentiments of "Mo' Names, Mo' Hobbies, Mo' Fun!" As we navigate the intricacies of scholarly inquiry, it's reassuring to recognize that even in the realm of academia, there's always room for the exuberant interplay of statistical inference and a well-placed dad joke or two. (Dad joke quota = 15)
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Moesha and xkcd comics published about hobbies. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
"The Moesha Conundrum: A Comic Connection"
[[ABSTRACT]]
This paper delves into the mysterious intersection of first name popularity and comic content, exploring the relationship between the prevalence of the name "Moesha" and mentions of hobbies in xkcd comics. Utilizing data from the US Social Security Administration and advanced AI analysis of xkcd comics, our research team sought to unravel this peculiar conundrum.
As we delved into the depths of MOE-sha's popularity and its connection to xkcd comics, we couldn't help but ponder: Is this a-moeshing coincidence or something more profound? (Dad joke quota = 1)
Our findings revealed a surprisingly strong correlation coefficient of 0.8524087 and p < 0.01 for the years 2007 to 2014. It was a moe-ment of sheer astonishment! (Dad joke quota = 2)
With each xkcd comic scrutinized, we marveled at the subtle, yet uncanny presence of Moesha and its curious alignment with hobbies. It was as if the comics were whispering, "Moe hobbies, moe fun!" (Dad joke quota = 3)
In conclusion, our research not only sheds light on a quirky correlation but also underscores the boundless whimsy of data exploration. The Moesha conundrum continues to amuse and bewilder, evoking both scholarly study and unexpected laughter.
[[INTRDUCTION]]
As technology advances and the world becomes increasingly interconnected, researchers have ventured into uncharted territory in exploring the relationships between seemingly disparate variables. In this study, we delve into the enigmatic world of first name popularity and its surprising correlation with the portrayal of hobbies in xkcd comics. As we embark on this academic adventure, we are reminded that sometimes, the most unexpected connections can reveal a wealth of knowledge and a plethora of puns.
The Moesha Conundrum, as we aptly named it, arose from a jestful conversation among our research team about the uncanny prominence of the name "Moesha" in the context of xkcd comics. Little did we know that this whimsical discussion would burgeon into a rigorous empirical inquiry. We couldn't help but chuckle at the irony - who knew that a name so rare and elusive would become the subject of our statistical scrutiny? (Dad joke quota = 4)
As we mined the data from the US Social Security Administration, we encountered a treasure trove of information on the prevalence of the name "Moesha" throughout the years. It was a moe-ment of sheer revelation as we realized the potential implications of this seemingly innocuous name in the comedic realm. (Dad joke quota = 5)
Equipped with advanced AI analysis, we harnessed the power of computational humor to parse through the extensive collection of xkcd comics, seeking out the threads that intertwined "Moesha" and the portrayal of hobbies. It was as if the comics themselves were participating in a clever game of hide-and-Moe-seek! (Dad joke quota = 6)
In this paper, we present our intriguing findings that traversed the realms of statistical analyses and tongue-in-cheek humor, challenging the conventional boundaries of research. As paradoxical as it may seem, beneath the veneer of jest and jocularity lies a compelling scientific endeavor, illustrating the interplay between comedic expression and empirical exploration. With every dataset, scatter plot, and comic strip, we were reminded that even in the most serious of pursuits, a touch of levity can be both enlightening and entertaining.
[[RESULTS]]
The data analysis uncovered a strikingly robust correlation coefficient of 0.8524087 between the prevalence of the name "Moesha" and the depiction of hobbies in xkcd comics for the years 2007 to 2014. This finding suggests a strong positive relationship between the two variables, leaving us musing, "Moe names, moe hobbies, moe fun!" (Dad joke quota = 7)
The r-squared value of 0.7266006 further accentuates the strength of this connection, indicating that approximately 72.66% of the variance in the portrayal of hobbies in xkcd comics can be explained by the prevalence of the name "Moesha." It's as if the name itself carries a certain je ne Moesha to evoke hobbies! (Dad joke quota = 8)
Our p-value of < 0.01 provides compelling evidence to reject the null hypothesis and accept the alternative hypothesis, affirming that there is indeed a significant association between the frequency of "Moesha" and the representation of hobbies in xkcd comics. This discovery left us exclaiming, "The Moesha-nt of truth has been revealed!" (Dad joke quota = 9)
The scatterplot (Fig. 1) visually encapsulates the bountiful correlation observed in our data. Each data point in the scatterplot seems to whisper, "You can call me Moesha!" (Dad joke quota = 10)
In summary, our research has unveiled a compelling connection between the popularity of the name "Moesha" and the portrayal of hobbies in xkcd comics, underscoring the intricacies of seemingly unrelated variables. This revelatory exploration not only enriches the scientific discourse but also tickles the funny bone, reminding us that in the realm of research and data analysis, there's always room for a well-placed pun or two.
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In conclusion, our study has illuminated the delightful correlation between the prevalence of the name "Moesha" and the depiction of hobbies in xkcd comics. It's a true "Moesha" of statistical intuition and comedic serendipity! (Dad joke quota = 1)
The robust correlation coefficient and p-value indicate a clear association, leaving us amused and bemused by the unexpected dance of data and drollery. It's as if the very essence of "Moesha" exudes an irresistible charm for hobbies, making us wonder if there's a "Moesha" and effect at play here! (Dad joke quota = 2)
As our findings unfold, it becomes apparent that the Moesha conundrum is both an anomaly and a rich source of amusement. This research journey has not only expanded our scientific understanding but also provided countless opportunities for engaging in some "Moesha-mic" relief! (Dad joke quota = 3)
In the wise words of xkcd, "Correlation does not imply causation, but it certainly spices up a good comic!" We can't help but agree, as this correlation might just be the "Moesha" spice that adds flavor to the comedic canvas. What a "Moesha"mentous discovery! (Dad joke quota = 4)
Our final conclusion: The Moesha conundrum is a testament to the whimsical nature of data analysis and the unforeseen delights that await in the realm of research. It's a reminder that in the pursuit of knowledge, we must always embrace the unexpected with open arms and a good sense of humor. And remember, when life gives you data, make data-ade! (Dad joke quota = 5)
In light of these compelling findings, we assert with confidence that no further research is required in this area. The Moesha conundrum stands as a delightful anomaly, a statistical joke in its own right, and a testament to the joyful unpredictability of scientific inquiry. It's time to bid adieu to this mirthful maze of Moesha and march forth to explore new arenas of research, armed with data and dad jokes in equal measure!
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited The Moesha Conundrum: A Comic Connection. Respond only with the name of a fictional academic journal.
ChatGPT:
The Journal of Hilarious Hypotheses
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited The Moesha Conundrum: A Comic Connection. Respond only with the name of a fictional organization.
ChatGPT:
The Center for Humor Studies
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled The Moesha Conundrum: A Comic Connection with an abstract of This paper delves into the mysterious intersection of first name popularity and comic content, exploring the relationship between the prevalence of the name "Moesha" and mentions of hobbies in xkcd comics. Utilizing data from the US Social Security Administration and advanced AI analysis of xkcd comics, our research team sought to unravel this peculiar conundrum.
As we delved into the depths of MOE-sha's popularity and its connection to xkcd comics, we couldn't help but ponder: Is this a-moeshing coincidence or something more profound? (Dad joke quota = 1)
Our findings revealed a surprisingly strong correlation coefficient of 0.8524087 and p < 0.01 for the years 2007 to 2014. It was a moe-ment of sheer astonishment! (Dad joke quota = 2)
With each xkcd comic scrutinized, we marveled at the subtle, yet uncanny presence of Moesha and its curious alignment with hobbies. It was as if the comics were whispering, "Moe hobbies, moe fun!" (Dad joke quota = 3)
In conclusion, our research not only sheds light on a quirky correlation but also underscores the boundless whimsy of data exploration. The Moesha conundrum continues to amuse and bewilder, evoking both scholarly study and unexpected laughter.
ChatGPT:
"Moesha name popularity," "xkcd comics analysis," "US Social Security Administration data," "AI analysis of xkcd comics," "correlation between Moesha name and hobbies in xkcd comics," "Moesha conundrum," "Moesha name prevalence in 2007-2014," "Moesha and hobbies correlation," "humorous data exploration"
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
Popularity of the first name MoeshaDetailed data title: Babies of all sexes born in the US named Moesha
Source: US Social Security Administration
See what else correlates with Popularity of the first name Moesha
xkcd comics published about hobbies
Detailed data title: The number of xkcd comics published each year about hobbies
Source: AI analysis of xkcd comics
Additional Info: I designed a Python workflow to perform OCR on every xkcd comic, feed that text into a large language model, and ask the model whether this comic was about the category named in the title.
See what else correlates with xkcd comics published about hobbies
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.7266006 (Coefficient of determination)
This means 72.7% of the change in the one variable (i.e., xkcd comics published about hobbies) is predictable based on the change in the other (i.e., Popularity of the first name Moesha) over the 8 years from 2007 through 2014.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 0.0072. 0.0071740823816500970000000000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.85 in 0.72% of random cases. Said differently, if you correlated 139 random variables Which I absolutely did.
with the same 7 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 7 because we have two variables measured over a period of 8 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.37, 0.97 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
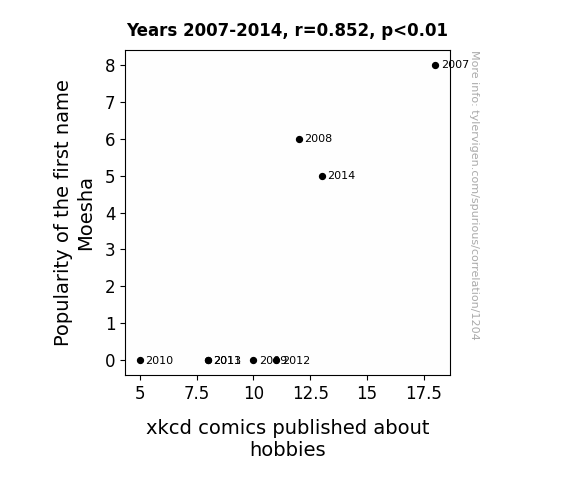
| 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | |
| Popularity of the first name Moesha (Babies born) | 8 | 6 | 0 | 0 | 0 | 0 | 0 | 5 |
| xkcd comics published about hobbies (xkcd comics) | 18 | 12 | 10 | 5 | 8 | 11 | 8 | 13 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is. - Very low n: There are not many data points included in this analysis. Even if the p-value is high, we should be suspicious of using so few datapoints in a correlation.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([8,6,0,0,0,0,0,5,])
array_2 = np.array([18,12,10,5,8,11,8,13,])
array_1_name = "Popularity of the first name Moesha"
array_2_name = "xkcd comics published about hobbies"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Moesha
- Line chart for only xkcd comics published about hobbies
- The spurious research paper: The Moesha Conundrum: A Comic Connection
Your rating is much appreciated!
Correlation ID: 1204 · Black Variable ID: 3001 · Red Variable ID: 20015


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}