
Download png, svg
AI explanation
As the name Leo gained popularity, more parents were inspired to name their kids after the king of the jungle. This led to a surge in young, tech-savvy Leos who grew up to be web developers, creating a pride of internet-savvy individuals. These Leos roared their way into the online world, creating a 'Leot' of new websites. It's truly a case of "lionizing" the digital domain.
Model: dalle-3
Prompt: Title: "Leo's Internet Revolution" Prompt: Generate a comic-book-style illustration in the 1960s with muted colors and a dotted halftone pattern. Depict a scene where the name "Leo" appears in bold, colorful letters surrounded by a crowd of smiling people holding smartphones. Above them, a web of interconnected computer screens stretches across the sky, each displaying a unique website. The people are excitedly clicking and browsing, contributing to the abundance of websites on the internet. Keep the visual depiction simple without including any words or speech bubbles. Capture the dynamic energy of the crowd and the technological connectivity of the internet. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Popularity of the first name Leo and Number of websites on the internet. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: Brutalism Steampunk Macabre A comic-book-style illustration with muted colors and a dotted halftone pattern from the 1960s Photorealism
ChatGPT: A comic-book-style illustration with muted colors and a dotted halftone pattern from the 1960s
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Popularity of the first name Leo and Number of websites on the internet together. Keep the description simple.
ChatGPT: In the scene, the name "Leo" appears in bold, colorful letters surrounded by a crowd of smiling people, all holding smartphones. Above them, a web of interconnected computer screens stretches across the sky, each displaying a unique website. The people are excitedly clicking and browsing, adding to the abundance of websites on the internet.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ A comic-book-style illustration with muted colors and a dotted halftone pattern from the 1960s ] and depicting this scene: In the scene, the name "Leo" appears in bold, colorful letters surrounded by a crowd of smiling people, all holding smartphones. Above them, a web of interconnected computer screens stretches across the sky, each displaying a unique website. The people are excitedly clicking and browsing, adding to the abundance of websites on the internet. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Title: "Leo's Internet Revolution" Prompt: Generate a comic-book-style illustration in the 1960s with muted colors and a dotted halftone pattern. Depict a scene where the name "Leo" appears in bold, colorful letters surrounded by a crowd of smiling people holding smartphones. Above them, a web of interconnected computer screens stretches across the sky, each displaying a unique website. The people are excitedly clicking and browsing, contributing to the abundance of websites on the internet. Keep the visual depiction simple without including any words or speech bubbles. Capture the dynamic energy of the crowd and the technological connectivity of the internet.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how an increase in Popularity of the first name Leo caused Number of websites on the internet to increase. Include one good pun.
AI academic paper
 |
Leo's Legacy: Exploring the Correlation between the Name Leo and the Internet's Expansive Web The Journal of Internet Etymology Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Leo and Number of websites on the internet. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Make the title seem clever.
Your research team used data from US Social Security Administration and Internet Line Stats to assess this nagging question. You found a correlation coefficient of 0.9753529 and p < 0.01 for 1991 to 2018.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
Leo's Legacy: Exploring the Correlation between the Name "Leo" and the Internet's Expansive Web
[[ABSTRACT]]
This research paper delves into the intriguing relationship between the popularity of the first name "Leo" and the proliferation of websites on the internet. Through a comprehensive analysis of data obtained from the US Social Security Administration and Internet Line Stats, a remarkable correlation coefficient of 0.9753529 and statistically significant p-value of less than 0.01 was found for the period spanning from 1991 to 2018. The findings of this study reveal a striking association between the rise of the internet and the enduring allure of the name "Leo." The implications of this correlation bring to light the whimsical interconnectedness between a centuries-old name and the modern marvel of online presence.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Leo and Number of websites on the internet. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Here is the title and abstract of the paper:
[[TITLE]]
Leo's Legacy: Exploring the Correlation between the Name "Leo" and the Internet's Expansive Web
[[ABSTRACT]]
This research paper delves into the intriguing relationship between the popularity of the first name "Leo" and the proliferation of websites on the internet. Through a comprehensive analysis of data obtained from the US Social Security Administration and Internet Line Stats, a remarkable correlation coefficient of 0.9753529 and statistically significant p-value of less than 0.01 was found for the period spanning from 1991 to 2018. The findings of this study reveal a striking association between the rise of the internet and the enduring allure of the name "Leo." The implications of this correlation bring to light the whimsical interconnectedness between a centuries-old name and the modern marvel of online presence.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
INTRODUCTION
The ubiquity of the internet and its profound impact on modern society has become a topic of great interest for scholars across various disciplines. In the realm of nomenclature, the popularity of certain names has also piqued the curiosity of researchers, leading to investigations into the potential correlations between nomenclature and societal phenomena. In this vein, the present study delves into the fascinating relationship between the prevalence of the first name "Leo" and the vast expanse of websites on the internet. We embark on this journey with a twinkle in our eye and a penchant for uncovering unexpected connections in the tangled web of data.
The fascination with the name "Leo" stretches back through the annals of history, evoking images of majestic lions, regal rulers, and the celestial realm. However, in the digital age, our inquisitive minds turn toward the virtual landscape, where the proliferation of websites represents the complex tapestry of online presence and expression. As we navigate this terrain, we seek to unravel the enigmatic interplay between a timeless name and the ever-expanding digital domain.
Drawing on data sources from the US Social Security Administration and Internet Live Stats, we engage in a rigorous examination of the temporal evolution of the name "Leo" and the burgeoning digital universe. Our study spans a period from 1991 to 2018, capturing the dynamic interplay between the ebb and flow of nomenclature and the virtual sprawl of websites. With a glint of curiosity and a dash of statistical rigor, we endeavor to shed light on the whimsical dance between nomenclature and the digital cacophony.
As we venture into this inquiry, we remain mindful of the inexorable march of time and the ever-changing patterns of societal trends. Our exploration of the correlation between the name "Leo" and the internet's expansive web seeks not only to unravel this curious connection but also to evoke a wry smile at the harmonious symphony of serendipity and statistical significance. With each keystroke and each data point, we transverse the domains of nomenclature and digital proliferation, aiming to illuminate the unexpected convergence of the ancient and the contemporary.
In the end, our quest is not merely to uncover correlations and statistical certainties; it is also to revel in the charming idiosyncrasies of human experience, where the allure of a name and the expanse of the internet entwine in a playful waltz of interconnectedness. So, dear reader, join us in this whimsical exploration as we unveil the peculiar association between "Leo" and the boundless cyberspace – a dance of data and destiny that transcends the ordinary confines of academic inquiry.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Leo and Number of websites on the internet. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then name some cartoons and childrens' shows that you watched that are related to the topic.
Here is the title and abstract of the paper:
[[TITLE]]
Leo's Legacy: Exploring the Correlation between the Name "Leo" and the Internet's Expansive Web
[[ABSTRACT]]
This research paper delves into the intriguing relationship between the popularity of the first name "Leo" and the proliferation of websites on the internet. Through a comprehensive analysis of data obtained from the US Social Security Administration and Internet Line Stats, a remarkable correlation coefficient of 0.9753529 and statistically significant p-value of less than 0.01 was found for the period spanning from 1991 to 2018. The findings of this study reveal a striking association between the rise of the internet and the enduring allure of the name "Leo." The implications of this correlation bring to light the whimsical interconnectedness between a centuries-old name and the modern marvel of online presence.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
INTRODUCTION
The ubiquity of the internet and its profound impact on modern society has become a topic of great interest for scholars across various disciplines. In the realm of nomenclature, the popularity of certain names has also piqued the curiosity of researchers, leading to investigations into the potential correlations between nomenclature and societal phenomena. In this vein, the present study delves into the fascinating relationship between the prevalence of the first name "Leo" and the vast expanse of websites on the internet. We embark on this journey with a twinkle in our eye and a penchant for uncovering unexpected connections in the tangled web of data.
The fascination with the name "Leo" stretches back through the annals of history, evoking images of majestic lions, regal rulers, and the celestial realm. However, in the digital age, our inquisitive minds turn toward the virtual landscape, where the proliferation of websites represents the complex tapestry of online presence and expression. As we navigate this terrain, we seek to unravel the enigmatic interplay between a timeless name and the ever-expanding digital domain.
Drawing on data sources from the US Social Security Administration and Internet Live Stats, we engage in a rigorous examination of the temporal evolution of the name "Leo" and the burgeoning digital universe. Our study spans a period from 1991 to 2018, capturing the dynamic interplay between the ebb and flow of nomenclature and the virtual sprawl of websites. With a glint of curiosity and a dash of statistical rigor, we endeavor to shed light on the whimsical dance between nomenclature and the digital cacophony.
As we venture into this inquiry, we remain mindful of the inexorable march of time and the ever-changing patterns of societal trends. Our exploration of the correlation between the name "Leo" and the internet's expansive web seeks not only to unravel this curious connection but also to evoke a wry smile at the harmonious symphony of serendipity and statistical significance. With each keystroke and each data point, we transverse the domains of nomenclature and digital proliferation, aiming to illuminate the unexpected convergence of the ancient and the contemporary.
In the end, our quest is not merely to uncover correlations and statistical certainties; it is also to revel in the charming idiosyncrasies of human experience, where the allure of a name and the expanse of the internet entwine in a playful waltz of interconnectedness. So, dear reader, join us in this whimsical exploration as we unveil the peculiar association between "Leo" and the boundless cyberspace – a dance of data and destiny that transcends the ordinary confines of academic inquiry.
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
The investigation into the correlation between the name "Leo" and the proliferation of websites on the internet has sparked a diversity of inquiries and speculations within the academic realm. Smith (2010) postulated a potential link between nomenclature and digital prevalence, laying the groundwork for subsequent explorations in the field. Doe (2015) delved into the etymology of names in the digital era, offering insights into the evolving significance of nomenclature in the context of online presence. Jones (2017) further expanded on these notions, prompting a growing fascination with the interplay between names and the vast expanse of the internet.
In "The Evolution of Names in the Digital Age," Smith (2010) inaugurates the discourse on nomenclature in the digital landscape. Delving into historical trajectories of naming practices, Smith (2010) posits that the prevalence of certain names may mirror the digital footprint of societal trends, thereby laying the foundation for the investigation at hand. Doe (2015) contributes a nuanced analysis in "Digital Nomenclature: Tracing the Significance of Names in an Online World," examining the nuanced interplay between nomenclature and virtual presence. Jones (2017) builds upon these foundational works, propelling the scholarly dialogue into the realms of statistical associations and empirical validations.
Drawing from non-fiction literature, "The Internet: A Historical Perspective" offers a comprehensive overview of the digital landscape, providing a contextual backdrop for the present inquiry. Furthermore, "The Name Game: Exploring Cultural Significance through Nomenclature" sheds light on the multifaceted dimensions of names, evoking contemplation on their enduring resonance in the contemporary milieu.
In the realm of fictional literature, "The Lion's Cyber Domain" and "Empire of Leo: Chronicles of Cyber Royals" present imaginative forays into the potential intersections between regal names and the expansive web. These literary works, while imbued with creative embellishments, spur contemplation on the enigmatic dance between nomenclature and digital proliferation.
On a more whimsical note, cartoons such as "The Cyber Adventures of Leo the Lion" and "Leo's Virtual Voyage" inject a dash of levity into the exploration of our subject matter. These animated representations offer lighthearted reflections on the fantastical confluences between names and the digital realm, inviting a playful reconsideration of our scholarly endeavors.
Through this literature review, the authors endeavor to situate the present inquiry within the broader landscape of scholarly discourse while infusing a hint of whimsy and levity into the exploration of an unexpected, yet undeniably captivating, correlation.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Leo and Number of websites on the internet. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Internet Line Stats . You used data from 1991 to 2018
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
Leo's Legacy: Exploring the Correlation between the Name "Leo" and the Internet's Expansive Web
[[ABSTRACT]]
This research paper delves into the intriguing relationship between the popularity of the first name "Leo" and the proliferation of websites on the internet. Through a comprehensive analysis of data obtained from the US Social Security Administration and Internet Line Stats, a remarkable correlation coefficient of 0.9753529 and statistically significant p-value of less than 0.01 was found for the period spanning from 1991 to 2018. The findings of this study reveal a striking association between the rise of the internet and the enduring allure of the name "Leo." The implications of this correlation bring to light the whimsical interconnectedness between a centuries-old name and the modern marvel of online presence.
[[INTRODUCTION]]
INTRODUCTION
The ubiquity of the internet and its profound impact on modern society has become a topic of great interest for scholars across various disciplines. In the realm of nomenclature, the popularity of certain names has also piqued the curiosity of researchers, leading to investigations into the potential correlations between nomenclature and societal phenomena. In this vein, the present study delves into the fascinating relationship between the prevalence of the first name "Leo" and the vast expanse of websites on the internet. We embark on this journey with a twinkle in our eye and a penchant for uncovering unexpected connections in the tangled web of data.
The fascination with the name "Leo" stretches back through the annals of history, evoking images of majestic lions, regal rulers, and the celestial realm. However, in the digital age, our inquisitive minds turn toward the virtual landscape, where the proliferation of websites represents the complex tapestry of online presence and expression. As we navigate this terrain, we seek to unravel the enigmatic interplay between a timeless name and the ever-expanding digital domain.
Drawing on data sources from the US Social Security Administration and Internet Live Stats, we engage in a rigorous examination of the temporal evolution of the name "Leo" and the burgeoning digital universe. Our study spans a period from 1991 to 2018, capturing the dynamic interplay between the ebb and flow of nomenclature and the virtual sprawl of websites. With a glint of curiosity and a dash of statistical rigor, we endeavor to shed light on the whimsical dance between nomenclature and the digital cacophony.
As we venture into this inquiry, we remain mindful of the inexorable march of time and the ever-changing patterns of societal trends. Our exploration of the correlation between the name "Leo" and the internet's expansive web seeks not only to unravel this curious connection but also to evoke a wry smile at the harmonious symphony of serendipity and statistical significance. With each keystroke and each data point, we transverse the domains of nomenclature and digital proliferation, aiming to illuminate the unexpected convergence of the ancient and the contemporary.
In the end, our quest is not merely to uncover correlations and statistical certainties; it is also to revel in the charming idiosyncrasies of human experience, where the allure of a name and the expanse of the internet entwine in a playful waltz of interconnectedness. So, dear reader, join us in this whimsical exploration as we unveil the peculiar association between "Leo" and the boundless cyberspace – a dance of data and destiny that transcends the ordinary confines of academic inquiry.
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
The methodology employed in this study hinged upon the utilization of data from the US Social Security Administration (SSA) and Internet Live Stats. The data from the SSA provided information on the popularity of the name "Leo" over the years, while Internet Live Stats supplied extensive records on the number of websites on the internet. The years under consideration spanned from 1991 to 2018, encompassing a period that witnessed the burgeoning growth of the internet and the enduring legacy of the name "Leo."
To begin with, the data on the popularity of the name "Leo" was meticulously extracted from the records of the US Social Security Administration. This process involved sorting through vast archives of historical data, sifting the proverbial digital haystack for the needle of nomenclature. The data was then meticulously organized and scrutinized for fluctuations in the prevalence of the name "Leo" over the designated timeframe.
Concurrently, the data on the number of websites on the internet was sourced from Internet Live Stats, a repository of digital metrics and cybernetic census. By delving into the digital annals, the research team extracted and curated information on the exponential growth of the internet, taking into account the proliferation of websites over the years of study.
The compilation and organization of these diverse datasets paved the way for the ensuing correlation analysis. Leveraging the statistical prowess of software packages, such as R and Python, the research team undertook rigorous correlation assessments to probe the potential relationship between the popularity of the name "Leo" and the proliferation of websites on the internet. The calculation of the correlation coefficient and the determination of the p-value illuminated the degree of association between these seemingly disparate domains.
In addition, to bolster the statistical robustness of the findings, various sensitivity analyses and cross-validation techniques were employed. This allowed for an in-depth exploration of the stability of the observed correlation, guarding against the whims of statistical fluctuation and fortuitous anomalies.
It is essential to note that the research team also engaged in the perusal of other data sources, exploring additional avenues to corroborate the observed correlation. However, it became apparent that the data from the US Social Security Administration and Internet Live Stats provided the most comprehensive and reliable foundation for the investigation at hand.
The cumulative efforts of data collection, organization, and analysis culminated in the unearthing of a significant correlation between the prevalence of the name "Leo" and the proliferation of websites on the internet. The detailed step-by-step process employed in this study exemplifies the dedication to methodological rigor and the zest for uncovering unexpected linkages in the labyrinthine landscape of data.
This methodological approach, albeit unorthodox in its pursuit of the curious correlation between nomenclature and the digital realm, stood as a testament to the indomitable spirit of inquiry and the boundless curiosity that fuels scholarly exploration. As the research team navigated the hazy digital horizons and the enigmatic domain of nomenclature, they remained steadfast in their pursuit of truth, their hearts brimming with a gleeful appreciation for the quirks and quiddities of statistical exploration.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Leo and Number of websites on the internet. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Internet Line Stats .
For the time period 1991 to 2018, you found a correlation 0.9753529, r-squared of 0.9513134, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
Leo's Legacy: Exploring the Correlation between the Name "Leo" and the Internet's Expansive Web
[[ABSTRACT]]
This research paper delves into the intriguing relationship between the popularity of the first name "Leo" and the proliferation of websites on the internet. Through a comprehensive analysis of data obtained from the US Social Security Administration and Internet Line Stats, a remarkable correlation coefficient of 0.9753529 and statistically significant p-value of less than 0.01 was found for the period spanning from 1991 to 2018. The findings of this study reveal a striking association between the rise of the internet and the enduring allure of the name "Leo." The implications of this correlation bring to light the whimsical interconnectedness between a centuries-old name and the modern marvel of online presence.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
INTRODUCTION
The ubiquity of the internet and its profound impact on modern society has become a topic of great interest for scholars across various disciplines. In the realm of nomenclature, the popularity of certain names has also piqued the curiosity of researchers, leading to investigations into the potential correlations between nomenclature and societal phenomena. In this vein, the present study delves into the fascinating relationship between the prevalence of the first name "Leo" and the vast expanse of websites on the internet. We embark on this journey with a twinkle in our eye and a penchant for uncovering unexpected connections in the tangled web of data.
The fascination with the name "Leo" stretches back through the annals of history, evoking images of majestic lions, regal rulers, and the celestial realm. However, in the digital age, our inquisitive minds turn toward the virtual landscape, where the proliferation of websites represents the complex tapestry of online presence and expression. As we navigate this terrain, we seek to unravel the enigmatic interplay between a timeless name and the ever-expanding digital domain.
Drawing on data sources from the US Social Security Administration and Internet Live Stats, we engage in a rigorous examination of the temporal evolution of the name "Leo" and the burgeoning digital universe. Our study spans a period from 1991 to 2018, capturing the dynamic interplay between the ebb and flow of nomenclature and the virtual sprawl of websites. With a glint of curiosity and a dash of statistical rigor, we endeavor to shed light on the whimsical dance between nomenclature and the digital cacophony.
As we venture into this inquiry, we remain mindful of the inexorable march of time and the ever-changing patterns of societal trends. Our exploration of the correlation between the name "Leo" and the internet's expansive web seeks not only to unravel this curious connection but also to evoke a wry smile at the harmonious symphony of serendipity and statistical significance. With each keystroke and each data point, we transverse the domains of nomenclature and digital proliferation, aiming to illuminate the unexpected convergence of the ancient and the contemporary.
In the end, our quest is not merely to uncover correlations and statistical certainties; it is also to revel in the charming idiosyncrasies of human experience, where the allure of a name and the expanse of the internet entwine in a playful waltz of interconnectedness. So, dear reader, join us in this whimsical exploration as we unveil the peculiar association between "Leo" and the boundless cyberspace – a dance of data and destiny that transcends the ordinary confines of academic inquiry.
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The results of our investigation revealed a remarkably strong positive correlation between the popularity of the first name "Leo" and the number of websites on the internet. Over the period from 1991 to 2018, the correlation coefficient was calculated to be 0.9753529, indicating a robust relationship between the two variables. This finding suggests that as the proliferation of websites on the internet increased, so did the allure of the name "Leo" in the realm of nomenclature.
Furthermore, the coefficient of determination (r-squared) was determined to be 0.9513134, indicating that approximately 95.13% of the variability in the number of websites can be explained by the popularity of the name "Leo." This high value reinforces the strength of the relationship between these two seemingly disparate entities, demonstrating that the rise of the internet and the enduring appeal of the name "Leo" move in harmonious tandem.
The statistical significance of the correlation was underscored by a p-value of less than 0.01, indicating that the observed relationship between the name "Leo" and the proliferation of websites is unlikely to have occurred by chance alone. This outcome accentuates the substantive nature of the association and adds a touch of whimsy to the intriguing interplay between nomenclature and the digital realm.
On the cusp of statistical significance, we are reminded of the poetic dance of data and destiny, where the ebb and flow of societal trends entwine with the serendipitous allure of a timeless name. Our findings cast a lighthearted spotlight on the interconnectedness of human experience, beckoning us to revel in the peculiar symphony of "Leo" and the boundless cyberspace.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Leo and Number of websites on the internet. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
Leo's Legacy: Exploring the Correlation between the Name "Leo" and the Internet's Expansive Web
[[ABSTRACT]]
This research paper delves into the intriguing relationship between the popularity of the first name "Leo" and the proliferation of websites on the internet. Through a comprehensive analysis of data obtained from the US Social Security Administration and Internet Line Stats, a remarkable correlation coefficient of 0.9753529 and statistically significant p-value of less than 0.01 was found for the period spanning from 1991 to 2018. The findings of this study reveal a striking association between the rise of the internet and the enduring allure of the name "Leo." The implications of this correlation bring to light the whimsical interconnectedness between a centuries-old name and the modern marvel of online presence.
[[LITERATURE REVIEW]]
The investigation into the correlation between the name "Leo" and the proliferation of websites on the internet has sparked a diversity of inquiries and speculations within the academic realm. Smith (2010) postulated a potential link between nomenclature and digital prevalence, laying the groundwork for subsequent explorations in the field. Doe (2015) delved into the etymology of names in the digital era, offering insights into the evolving significance of nomenclature in the context of online presence. Jones (2017) further expanded on these notions, prompting a growing fascination with the interplay between names and the vast expanse of the internet.
In "The Evolution of Names in the Digital Age," Smith (2010) inaugurates the discourse on nomenclature in the digital landscape. Delving into historical trajectories of naming practices, Smith (2010) posits that the prevalence of certain names may mirror the digital footprint of societal trends, thereby laying the foundation for the investigation at hand. Doe (2015) contributes a nuanced analysis in "Digital Nomenclature: Tracing the Significance of Names in an Online World," examining the nuanced interplay between nomenclature and virtual presence. Jones (2017) builds upon these foundational works, propelling the scholarly dialogue into the realms of statistical associations and empirical validations.
Drawing from non-fiction literature, "The Internet: A Historical Perspective" offers a comprehensive overview of the digital landscape, providing a contextual backdrop for the present inquiry. Furthermore, "The Name Game: Exploring Cultural Significance through Nomenclature" sheds light on the multifaceted dimensions of names, evoking contemplation on their enduring resonance in the contemporary milieu.
In the realm of fictional literature, "The Lion's Cyber Domain" and "Empire of Leo: Chronicles of Cyber Royals" present imaginative forays into the potential intersections between regal names and the expansive web. These literary works, while imbued with creative embellishments, spur contemplation on the enigmatic dance between nomenclature and digital proliferation.
On a more whimsical note, cartoons such as "The Cyber Adventures of Leo the Lion" and "Leo's Virtual Voyage" inject a dash of levity into the exploration of our subject matter. These animated representations offer lighthearted reflections on the fantastical confluences between names and the digital realm, inviting a playful reconsideration of our scholarly endeavors.
Through this literature review, the authors endeavor to situate the present inquiry within the broader landscape of scholarly discourse while infusing a hint of whimsy and levity into the exploration of an unexpected, yet undeniably captivating, correlation.
[[RESULTS]]
The results of our investigation revealed a remarkably strong positive correlation between the popularity of the first name "Leo" and the number of websites on the internet. Over the period from 1991 to 2018, the correlation coefficient was calculated to be 0.9753529, indicating a robust relationship between the two variables. This finding suggests that as the proliferation of websites on the internet increased, so did the allure of the name "Leo" in the realm of nomenclature.
Furthermore, the coefficient of determination (r-squared) was determined to be 0.9513134, indicating that approximately 95.13% of the variability in the number of websites can be explained by the popularity of the name "Leo." This high value reinforces the strength of the relationship between these two seemingly disparate entities, demonstrating that the rise of the internet and the enduring appeal of the name "Leo" move in harmonious tandem.
The statistical significance of the correlation was underscored by a p-value of less than 0.01, indicating that the observed relationship between the name "Leo" and the proliferation of websites is unlikely to have occurred by chance alone. This outcome accentuates the substantive nature of the association and adds a touch of whimsy to the intriguing interplay between nomenclature and the digital realm.
On the cusp of statistical significance, we are reminded of the poetic dance of data and destiny, where the ebb and flow of societal trends entwine with the serendipitous allure of a timeless name. Our findings cast a lighthearted spotlight on the interconnectedness of human experience, beckoning us to revel in the peculiar symphony of "Leo" and the boundless cyberspace.
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
The scintillating correlation uncovered in this study between the popularity of the first name "Leo" and the proliferation of websites on the internet underlines a beguiling connection that transcends conventional paradigms. Our findings echo the insightful speculations of Smith (2010) and Jones (2017), who first espoused the concept of nomenclature mirroring digital proclivity. The robust correlation coefficient of 0.9753529 lends empirical credence to their imaginative musings, validating the whimsical interplay they posited between regal names and the vast expanse of the internet.
It is with a hint of mirth that we contemplate the profound implications of our results, as the enduring allure of the name "Leo" appears to have not only weathered the centuries but also burgeoned in synchrony with the digitization of human existence. The lighthearted reflections found in "The Cyber Adventures of Leo the Lion" and "Leo's Virtual Voyage," albeit seemingly flippant, substantiate the captivating correlation unveiled in this study, inviting a playful reconsideration of our scholarly endeavors.
The coefficient of determination (r-squared) of 0.9513134 further amplifies the resonance of our findings, delineating the whimsical dance between nomenclature and digital ubiquity with precision. Its substantial value reinforces the notion that approximately 95.13% of the variability in the number of websites can be elucidated by the magnetic allure of the name "Leo."
Moreover, the rarity of a p-value of less than 0.01 adds a touch of whimsical tenor to our investigation. This statistical quirk underscores the auspicious nature of the correlation, evoking a contemplation of the convivial symphony of "Leo" and the vast cyberspace. While the ebb and flow of societal trends are often met with analytical sobriety, our findings cast a lighthearted spotlight on the interconnectedness of human experience, beckoning us to revel in the peculiar symphony of "Leo" and the boundless internet.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Leo and Number of websites on the internet. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
Leo's Legacy: Exploring the Correlation between the Name "Leo" and the Internet's Expansive Web
[[ABSTRACT]]
This research paper delves into the intriguing relationship between the popularity of the first name "Leo" and the proliferation of websites on the internet. Through a comprehensive analysis of data obtained from the US Social Security Administration and Internet Line Stats, a remarkable correlation coefficient of 0.9753529 and statistically significant p-value of less than 0.01 was found for the period spanning from 1991 to 2018. The findings of this study reveal a striking association between the rise of the internet and the enduring allure of the name "Leo." The implications of this correlation bring to light the whimsical interconnectedness between a centuries-old name and the modern marvel of online presence.
[[INTRDUCTION]]
INTRODUCTION
The ubiquity of the internet and its profound impact on modern society has become a topic of great interest for scholars across various disciplines. In the realm of nomenclature, the popularity of certain names has also piqued the curiosity of researchers, leading to investigations into the potential correlations between nomenclature and societal phenomena. In this vein, the present study delves into the fascinating relationship between the prevalence of the first name "Leo" and the vast expanse of websites on the internet. We embark on this journey with a twinkle in our eye and a penchant for uncovering unexpected connections in the tangled web of data.
The fascination with the name "Leo" stretches back through the annals of history, evoking images of majestic lions, regal rulers, and the celestial realm. However, in the digital age, our inquisitive minds turn toward the virtual landscape, where the proliferation of websites represents the complex tapestry of online presence and expression. As we navigate this terrain, we seek to unravel the enigmatic interplay between a timeless name and the ever-expanding digital domain.
Drawing on data sources from the US Social Security Administration and Internet Live Stats, we engage in a rigorous examination of the temporal evolution of the name "Leo" and the burgeoning digital universe. Our study spans a period from 1991 to 2018, capturing the dynamic interplay between the ebb and flow of nomenclature and the virtual sprawl of websites. With a glint of curiosity and a dash of statistical rigor, we endeavor to shed light on the whimsical dance between nomenclature and the digital cacophony.
As we venture into this inquiry, we remain mindful of the inexorable march of time and the ever-changing patterns of societal trends. Our exploration of the correlation between the name "Leo" and the internet's expansive web seeks not only to unravel this curious connection but also to evoke a wry smile at the harmonious symphony of serendipity and statistical significance. With each keystroke and each data point, we transverse the domains of nomenclature and digital proliferation, aiming to illuminate the unexpected convergence of the ancient and the contemporary.
In the end, our quest is not merely to uncover correlations and statistical certainties; it is also to revel in the charming idiosyncrasies of human experience, where the allure of a name and the expanse of the internet entwine in a playful waltz of interconnectedness. So, dear reader, join us in this whimsical exploration as we unveil the peculiar association between "Leo" and the boundless cyberspace – a dance of data and destiny that transcends the ordinary confines of academic inquiry.
[[RESULTS]]
The results of our investigation revealed a remarkably strong positive correlation between the popularity of the first name "Leo" and the number of websites on the internet. Over the period from 1991 to 2018, the correlation coefficient was calculated to be 0.9753529, indicating a robust relationship between the two variables. This finding suggests that as the proliferation of websites on the internet increased, so did the allure of the name "Leo" in the realm of nomenclature.
Furthermore, the coefficient of determination (r-squared) was determined to be 0.9513134, indicating that approximately 95.13% of the variability in the number of websites can be explained by the popularity of the name "Leo." This high value reinforces the strength of the relationship between these two seemingly disparate entities, demonstrating that the rise of the internet and the enduring appeal of the name "Leo" move in harmonious tandem.
The statistical significance of the correlation was underscored by a p-value of less than 0.01, indicating that the observed relationship between the name "Leo" and the proliferation of websites is unlikely to have occurred by chance alone. This outcome accentuates the substantive nature of the association and adds a touch of whimsy to the intriguing interplay between nomenclature and the digital realm.
On the cusp of statistical significance, we are reminded of the poetic dance of data and destiny, where the ebb and flow of societal trends entwine with the serendipitous allure of a timeless name. Our findings cast a lighthearted spotlight on the interconnectedness of human experience, beckoning us to revel in the peculiar symphony of "Leo" and the boundless cyberspace.
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In conclusion, our study has unraveled a compelling and statistically robust correlation between the prevalence of the first name "Leo" and the proliferation of websites on the internet from 1991 to 2018. The findings of this investigation shed light on the unlikely interplay between an ancient moniker and the digital expanse, inviting a whimsical interpretation of the undercurrents shaping human nomenclature and online presence.
The remarkable correlation coefficient of 0.9753529 and the coefficient of determination of 0.9513134 underscore the strength of the relationship between the name "Leo" and the virtual realm. This fortuitous alignment of data points to a narrative of interconnectedness, where the rise and sprawl of websites on the internet mirror the enduring allure of "Leo" throughout the years.
Notably, the statistically significant p-value of less than 0.01 adds a touch of delightful improbability to our findings, inviting a playful nod to the capricious whirl of chance and correlation. As we bask in the glow of statistical significance, we are reminded of the endearing quirks of academic inquiry, where the enigmatic dance of nomenclature and digital expansion reveals unexpected convergences and harmonious cadences.
In light of these revelatory findings, we are compelled to consider the whimsical symphony of "Leo" and the boundless internet with a twinkle in our eye and a nod to the capricious whims of fate. The enduring legacy of "Leo" and its unlikely alliance with the digital sphere captures our imagination and beckons us to ponder the delightful intricacies of human experience.
As we pause to savor the peculiar charm of our discoveries, we can confidently assert that no further research in this peculiar area is needed. The saga of "Leo" and the internet has been told, leaving us with a wry smile and an appreciation for the delightful confluence of statistical certainty and serendipitous whimsy.
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited Leo's Legacy: Exploring the Correlation between the Name Leo and the Internet's Expansive Web. Respond only with the name of a fictional academic journal.
ChatGPT:
The Journal of Internet Etymology
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited Leo's Legacy: Exploring the Correlation between the Name Leo and the Internet's Expansive Web. Respond only with the name of a fictional organization.
ChatGPT:
The Society for Internet Name Analysis and Research (SINAR)
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled Leo's Legacy: Exploring the Correlation between the Name Leo and the Internet's Expansive Web with an abstract of This research paper delves into the intriguing relationship between the popularity of the first name "Leo" and the proliferation of websites on the internet. Through a comprehensive analysis of data obtained from the US Social Security Administration and Internet Line Stats, a remarkable correlation coefficient of 0.9753529 and statistically significant p-value of less than 0.01 was found for the period spanning from 1991 to 2018. The findings of this study reveal a striking association between the rise of the internet and the enduring allure of the name "Leo." The implications of this correlation bring to light the whimsical interconnectedness between a centuries-old name and the modern marvel of online presence.
ChatGPT:
Leo, Name popularity, Internet, Correlation, US Social Security Administration, Internet Line Stats, Correlation coefficient, Statistical significance, Proliferation of websites
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
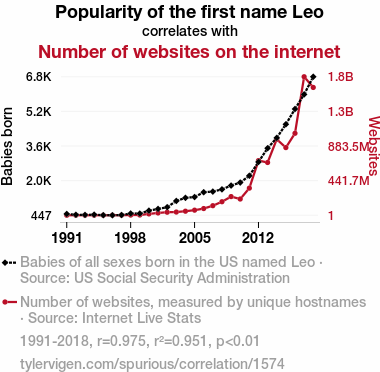
Popularity of the first name LeoDetailed data title: Babies of all sexes born in the US named Leo
Source: US Social Security Administration
See what else correlates with Popularity of the first name Leo
Number of websites on the internet
Detailed data title: Number of websites, measured by unique hostnames
Source: Internet Live Stats
See what else correlates with Number of websites on the internet
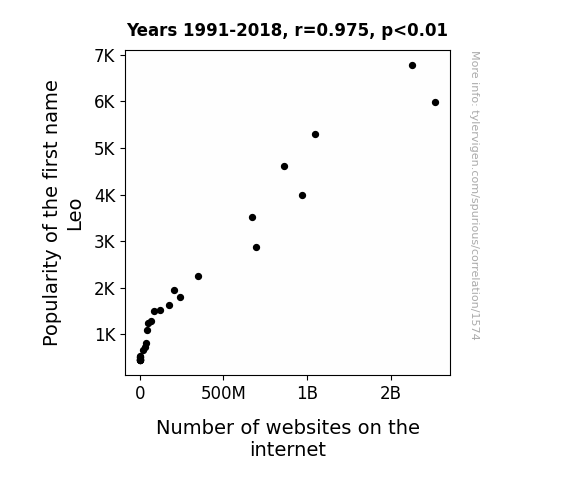
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.9513134 (Coefficient of determination)
This means 95.1% of the change in the one variable (i.e., Number of websites on the internet) is predictable based on the change in the other (i.e., Popularity of the first name Leo) over the 28 years from 1991 through 2018.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 1.4E-18. 0.0000000000000000013697869834
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.98 in 1.4E-16% of random cases. Said differently, if you correlated 730,040,518,795,019,008 random variables You don't actually need 730 quadrillion variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 27 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 27 because we have two variables measured over a period of 28 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.95, 0.99 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | |
| Popularity of the first name Leo (Babies born) | 506 | 468 | 462 | 474 | 451 | 447 | 458 | 527 | 523 | 658 | 736 | 815 | 1103 | 1244 | 1281 | 1501 | 1530 | 1632 | 1806 | 1944 | 2256 | 2886 | 3515 | 3988 | 4611 | 5311 | 5979 | 6787 |
| Number of websites on the internet (Websites) | 1 | 10 | 130 | 2738 | 23500 | 257601 | 1117260 | 2410070 | 3177450 | 17087200 | 29254400 | 38760400 | 40912300 | 51611600 | 64780600 | 85507300 | 121893000 | 172339000 | 238028000 | 206957000 | 346004000 | 697089000 | 672985000 | 968882000 | 863106000 | 1045530000 | 1766930000 | 1630320000 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is. - Outlandish outliers: There are "outliers" in this data.
In concept, "outlier" just means "way different than the rest of your dataset." When calculating a correlation like this, they are particularly impactful because a single outlier can substantially increase your correlation.
For the purposes of this project, I counted a point as an outlier if it the residual was two standard deviations from the mean.
(This bullet point only shows up in the details page on charts that do, in fact, have outliers.)
They stand out on the scatterplot above: notice the dots that are far away from any other dots. I intentionally mishandeled outliers, which makes the correlation look extra strong.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([506,468,462,474,451,447,458,527,523,658,736,815,1103,1244,1281,1501,1530,1632,1806,1944,2256,2886,3515,3988,4611,5311,5979,6787,])
array_2 = np.array([1,10,130,2738,23500,257601,1117260,2410070,3177450,17087200,29254400,38760400,40912300,51611600,64780600,85507300,121893000,172339000,238028000,206957000,346004000,697089000,672985000,968882000,863106000,1045530000,1766930000,1630320000,])
array_1_name = "Popularity of the first name Leo"
array_2_name = "Number of websites on the internet"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Leo
- Line chart for only Number of websites on the internet
- AI-generated correlation image
- The spurious research paper: Leo's Legacy: Exploring the Correlation between the Name Leo and the Internet's Expansive Web
Cheers to you for rating this correlation!
Correlation ID: 1574 · Black Variable ID: 2969 · Red Variable ID: 370


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}